Setting up an Amazon S3 Compatible Object Store¶
Installation and configuration of the TeamDrive S3 Daemon s3d is only required if TSHS (see TeamDrive Scalable Hosting Storage for details) is not enabled and you have an Amazon S3 compatible object store you wish to use as a secondary storage tier. Currently, Amazon S3 and OpenStack are supported.
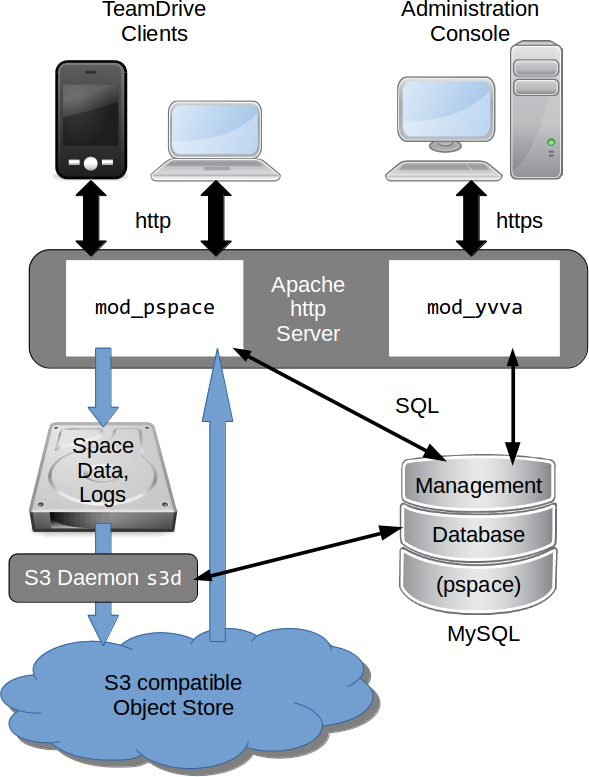
TeamDrive Hosting Service using an S3-compatible object store
s3d is a process that runs in the background and provides secondary storage by transferring files to the object store. It does this by monitoring the hosted data directory structure and transferring files to the object store when a file reaches an age as specified in the service’s configuration. The configuration settings also allows you to specify what files are eligible to be transferred via the use of pattern matching.
Note
Because all object store requests will be signed using the current timestamp, it’s essential that the system time is accurate when running s3d. Make sure that the NTP service is installed and running. See the chapters about NTP configuration in the installation guides for details.
Configuring s3d¶
The configuration of s3d is performed by changing the relevant configuration settings using the Host Server Administration Console.
Log into your Host Servers Administration Console at https://hostserver.yourdomain.com/admin/ and click on Settings. The S3 daemon Settings all begin with S3.
The following information is needed by s3d to connect to the object store.
- S3Brand
- This setting specifies the type of S3 storage. Valid options are: Amazon or OpenStack.
- S3Server
- Your object store’s domain name, e.g. s3.amazonaws.com.
- S3DataBucketName
- The name of the Bucket in the object store that will contain the Space data. The bucket must already exist.
Warning
If you are setting up multiple TeamDrive Hosting servers it is important that they do not use the same Bucket. Doing so can result in data loss.
- S3AccessKey
- Your S3 access (public) key, used to access the specified bucket.
- S3SecretKey
- Your S3 secret (private) key used to access the specified bucket.
- S3SyncActive
- Set this to True to enable the synchronization of data stored by the Host Server (Space data) to the specified bucket on an S3 compatible object store. Note that the synchronization won’t start until the s3d service has been started (see below).
- S3Options
- These options control the way S3 is accessed, for example the number of parallel threads during upload, whether to use multipart upload, etc. The options may also contain S3Brand specific settings.
- S3EnableRedirect
- When S3 redirect is enabled, the Host Server will redirect the Client to a download directly from the object store, when appropriate. This helps to offload traffic from the Host Server to the object store. If set to False, the Host Server fetches the requested object from the object store and serves it to the Client directly.
Starting and Stopping the s3d service¶
You can use the /etc/init.d/s3d init script to start and stop s3d. The configuration setting S3SyncActive needs to be set to True, otherwise s3d will abort with a corresponding error message.
Warning
Enabling the S3 Daemon means that any new data in existing Spaces and new Spaces will be transferred to the object store. Currently, there is no automatic way to return back to a pure file-based Host Server setup — data that was moved to S3 stays in S3. Disabling the S3 secondary storage tier would result in Clients no longer being able to access their Space data.
After starting s3d with the command service s3d start, check the log file /var/log/s3d.log for startup messages. You can use service s3d status to check if s3d is up and running.
s3d should be added to the processes to be started at boot time. To do this execute the following commands as root:
[root@hostserver ~]# chkconfig s3d on
Optional configuration parameters¶
The following optional configuration options can be modified in the S3Options configuration setting:
- MinBlockSize
- The minimum block size that can be used for multi-part upload. The valid range of this parameter will be determined by the implementation of the object store being used.
- MaxUploadParts
- The maximum number of parts a file can be divided into for upload. The valid range of this parameter will be determined by the implementation of the object store being used.
- MaxFileUploadSize
- Files larger than this will not be transferred to S3. The default, 0, means all files are uploaded.
- MaxUploadThreads
- The thread pool size to use for multi-part uploads. The default, 0, means single threaded.
- BucketAsSubdomain
- Amazon S3 uses the bucket name as part of the domain name (BucketAsSubdomain=1), while other S3-compatible object stores (e.g. OpenStack) include the bucket name as part of the path name after the domain (BucketAsSubdomain=0). This option usually does not have to be set explicitly, as the S3Brand setting determines this value automatically.
OpenStack configuration parameters¶
If the S3Brand is set to OpenStack then 2 additional parameters are required in S3Options, to enable the generation of temporary URLs. Temporary URLs give clients temporary direct access to objects in the object store, helping to reduce network traffic on the Host Server. This requires the setting S3EnableRedirect to be set to True.
- OpenStackAuthPath
- This is the path component of the OpenStack Authorization URL. For example if the OpenStack Authorization URL is https://swift-cluster.example.com/v1/AUTH_a422b2-91f3-2f46-74b7-d7c9e8958f5d30 then the OpenStackAuthPath would be /v1/AUTH_a422b2-91f3-2f46-74b7-d7c9e8958f5d30.
- OpenStackAuthKey
- Your OpenStack temp URL key used to generate temporary URLs.
Your OpenStack administrator should be able to provide you with the OpenStack Authorization URL and the corresponding temp URL key.
Warning
The generation of new temp URL keys will invalidate older keys. It is important that once the temp URL key has been set for your TeamDrive Hosting server that no new keys are being generated.
Enabling Object Store Traffic Usage Processing¶
When S3 storage has been enabled, TeamDrive Clients access the data in the object store directly. The traffic required by these operations is recorded by reading the S3 access log files.
This means that setting S3SyncActive to True changes the way Traffic usage is calculated. When S3SyncActive to False, the Hosting Service is able to record all traffic usage in the pspace database. When S3SyncActive to True the S3 access logs myst be downloaded and parsed to get the required information.
Note
The traffic usage processing expects the Amazon S3 access log format.
The calculation of traffic usage requires an external Perl-based tool named aws to be installed. Install the aws tool as described on its home page at http://timkay.com/aws/. The tools s3get, s3ls and s3delete need to be in the PATH of the apache user.
In addition, the following configuration settings have to be defined:
- S3LogBucketName:
- Name of the bucket that contains the S3 access logs. Note that if this setting is empty, the object store traffic will not be calculated. You must configure your object store to save the access logs to this bucket. Please refer to your object store documentation to determine how this is done.
- S3ToProcessPath:
- Local path in the filesystem to download above access logs for further processing. By default, this path is set to /var/opt/teamdrive/td-hostserver/s3-logs-incoming/
- S3ArchiveLogs:
- If set to True, the processed access logs will be moved to the folder defined in the next setting S3ProcessedPath.
- S3ProcessedPath:
- If logs need to be kept for own additional analysing, then the S3 log files will be moved to this directory once traffic usage Processing is complete.
By default, the task that calculates the S3 traffic runs every 10 minutes.